– Arief Prihantoro –

Wajah adalah kanvas emosi yang paling jujur. Gerakan kecil di sudut bibir atau kerutan pada dahi sering berbicara lebih banyak daripada kata-kata. Otak kita, sebagai hasil evolusi jutaan tahun, sudah sangat piawai membaca isyarat halus ini secara otomatis. Bahkan sebelum kita menyadarinya, otak sudah menebak: “Dia sedang senang,” atau “Ada yang membuatnya terkejut”. Artikel ini akan menunjukkan bagaimana kecerdasan buatan (AI) mencoba meniru cara kerja otak itu—mulai dari mengamati gambar wajah hingga menghubungkan dengan “percakapan” tentang gambar tersebut.
Bagaimana Otak Manusia Melihat dan Membaca Ekspresi
Pertama-tama, kita lihat bagaimana otak manusia mengenali ekspresi. Mata kita bertindak layaknya kamera biologis. Retina menangkap cahaya dan pola, lalu mengubahnya menjadi sinyal listrik yang dikirim lewat saraf optik ke otak. Namun retina kita lebih dari sekedar kamera pasif: ia punya jutaan sel reseptor (rod dan cone) yang masing-masing peka terhadap pola tertentu, seperti garis, lengkungan, titik terang, atau warna.
Setelah sinyal mencapai otak, muncullah korteks visual, pusat pemrosesan penglihatan. Bayangkan korteks visual seperti pabrik analisis gambar: setiap kelompok neuron di sini punya tugas khusus. Misalnya, satu kelompok sangat peka pada garis vertikal, kelompok lain mengenali lengkungan halus, dan kelompok lain lagi bisa mendeteksi titik-titik terang. Hasil kerja tiap kelompok neuron inilah yang kemudian disatukan, sehingga kita memiliki gambaran lengkap tentang apa yang sedang kita lihat.
Salah satu tantangan terbesar dalam membaca wajah adalah ekspresi emosi secara mikro: perubahan otot wajah sekecil kedipan singkat yang hanya berlangsung seperempat detik. Ekspresi mikro seringkali mengungkap perasaan tersembunyi, seperti kegembiraan yang disembunyikan atau kegelisahan. Otak kita sangat mahir menangkap isyarat semacam ini karena ada jutaan “neuron visual” yang bekerja sangat cepat. Intinya, otak melihat wajah manusia seperti menyimak cerita rumit dari banyak sinyal kecil secara simultan.
AI Meniru Cara Kerja Otak Biologis
AI modern, terutama yang menggunakan deep learning, berusaha meniru mekanisme tersebut. Alih-alih sel biologis, AI menggunakan neuron digital—unit matematis yang memproses angka. Saat sebuah model AI “melihat” gambar, ia tidak menangkap gambar utuh sekaligus, melainkan membaginya menjadi ribuan sinyal kecil: warna, gradien terang–gelap, tepian obyek gambar, lengkungan, tekstur, dsb. Disebut patch, kalau dalam arsitektur Computer Vision, seperti arsitektur Vision Transformer misalnya. Patch ini kalau dalam arsitektur Semantik AI (model LLM) disebut dengan token, semisal dalam arsitektur NLP Transformer..
Prosesnya berlapis-lapis, mirip hierarki otak. Lapisan-lapisan awal dalam jaringan saraf mendeteksi pola sederhana, seperti garis atau tepi gambar. Lapisan-lapisan berikutnya menggabungkan pola tersebut menjadi bentuk lebih kompleks, seperti mata atau mulut, dan lapisan terdalam akhirnya bisa mengaitkan bentuk-bentuk itu dengan ekspresi tertentu (misalnya senyum atau cemberut). Semakin dalam lapisan, pemahamannya semakin abstrak. Analogi sederhananya, lapisan pertama seperti melempar tepung ke udara dan melihat butirannya, sementara lapisan terakhir seperti membaca pesan yang tertulis halus di udara tersebut.
Untuk mengenali ekspresi wajah, banyak sistem AI menggunakan MobileNetV2, sebuah arsitektur jaringan saraf yang ringan. Pada lapisan akhirnya, MobileNetV2 salah satu modenya memiliki sekitar 1280 neuron visual. Bayangkan otak visual kita memiliki 1280 jenis sel deteksi pola. Setiap jenis “sel” (neuron digital) itu punya tugas spesifik. Misalnya, satu sel bisa peka pada kerutan kecil di sudut mata, sel lain mendeteksi gerakan pipi, sel lain mengenali garis halus di bawah hidung—dan seterusnya hingga 1280 jenis pola. Semakin banyak jenis detektor yang ada, semakin lengkap dan tajam gambaran wajah yang diperoleh komputer.
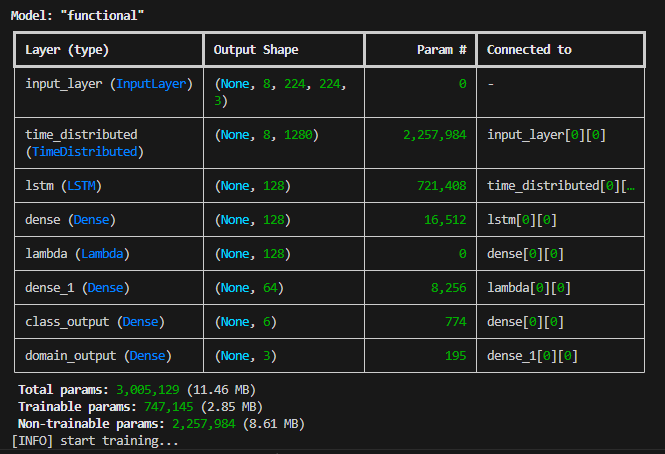
Tabel arsitektur model diatas bisa dianalogikan dengan salah satu fungsi otak, yaitu cara kerja otak visual. Setiap baris layer adalah satu tahapan fungsi dari sekumpulan neuron, sejak mulai obyek gambar visual ditangkap oleh kornea mata sebagai layer pertama, hingga layer paling bawah adalah outputnya, dimana kemudian otak memahami gambar atau obyek apa yg dilihat atau ditangkap oleh mata biologis.
Setiap layer adalah sekumpulan neuron, bukan neuron tungal. Layer pertama (input layer) bisa diibaratkan dengan kornea, kornea juga terhubung dengan neuron, dia berfungsi sebagai layer pertama ketika otak melihat obyek yang dilihat oleh mata melalui kornea mata dan kemudian diteruskan ke layer kedua. Layer kedua bisa diibaratkan dengan retina mata, dimana obyek yg ditangkap oleh mata diurai menjadi sinyal-sinyal cahaya yang berbeda-beda untuk diteruskan ke 1280 neuron visual. Di dalam neuran visual tersebut kemudian sinyal diterjemahkan atau dikalkulasi secara matematis kalau dalam terminologi AI. Masing-masing neuron diantara 1280 neuron dalam layer kedua tersebut memiliki fungsi yang berbeda-beda dalam melakukan kalkulasi. Dan seterusnya hingga proses dilanjutkan sampai layer terakhir (layer domain_output) dimana otak menerjemahkan atau menginterpretasikan obyek yang ditangkap oleh kornea mata sebagai layer pertama, sehingga kita memahami obyek apa yang sedang kita lihat.
Jika kita mengurangi jumlah neuron visual ini, ketelitian AI juga berkurang. Misalnya, dari 1280 turun ke 640 atau 256, AI masih bisa “melihat” wajah secara umum, tetapi detail halus (yang krusial untuk ekspresi mikro) jadi sulit ditangkap. Analogi biologisnya seperti mengurangi sel peka di retina; mata masih bisa melihat bayangan wajah, tapi objek kecil menjadi kabur. Jadi dalam sistem pengenalan ekspresi, menjaga sebanyak 1280 neuron visual membuat AI tetap tajam seperti mata berkacamata.
Namun, sedikit penurunan kapasitas (misalnya 1280 menjadi sekitar 960) masih aman. Dalam beberapa varian MobileNetV2 (dengan “alpha 0.75”), jumlah internal neuron berkurang, tetapi neuron-neuron utama tetap utuh (1280). Ini mirip dengan melepas beberapa sel kurang penting di retina: namun masih terlihat jelas apa yang penting. Hasilnya, kualitas deteksi ekspresi tidak turun drastis, seperti mata berkacamata minus 0,5 atau 0,75 di lensa masih bisa mengenali teman lama. Artinya, penurunan kecil tak merusak kemampuan AI secara signifikan, selama “inti penglihatannya” tetap lengkap.
Membaca Video dan Gerakan Obyek dengan AI
Manusia tidak menilai ekspresi dari foto tunggal saja, melainkan dari gerakan antar-frame. Wajah yang berkedip atau alis yang berkerut bergerak menandakan emosi tertentu yang terekam dalam beberapa milidetik. AI pun meniru hal ini. Setiap frame video diproses secara berurutan oleh apa yang bisa disebut “korteks visual digital” model AI. Teknologi yang digunakan umumnya dikenal sebagai TimeDistributed: setiap foto dalam video dianalisis satu per satu, seakan-akan otak melihat rangkaian gambar demi gambar yang mengalir secara berurutan menjadi gambar bergerak.
Setelah itu, AI menggabungkan informasi setiap frame layaknya “memori jangka pendek”. Ada bagian dalam model yang berfungsi mirip hippocampus manusia. Bagian ini membandingkan frame pertama dan terakhir, membaca pola perubahan kecil di antaranya, lalu menyimpulkan: “Gerakan mata dan mulut kecil ini menunjukkan emosi tertentu”. Pendeknya, AI bukan hanya mengenali apa yang tampak di satu gambar, tetapi juga bagaimana itu berubah dari waktu ke waktu (TimeDistributed). Gerakan-gerakan cepat wajah (dalam satuan milidetik ekspresi mikro) inilah yang sering menjadi petunjuk emosi tersembunyi. Dengan strategi seperti otak, AI jadi lebih jeli menangkap ekspresi mikro yang muncul dalam video.
Vision-Language Models: AI yang “Melihat” dan “Berbicara”
Di samping membaca ekspresi, kini banyak AI yang bisa melihat gambar dan “berbicara” dalam bentuk teks. Model-model seperti ini disebut Vision-Language Models (VLM). Bayangkan mereka seperti pemandu wisata AI yang pintar: bisa melihat lanskap (gambar) sekaligus menjelaskan apa yang dilihat dengan kata-kata. VLM mengombinasikan penglihatan komputer (computer vision) dan pemrosesan bahasa (natural language).
Keahlian utama VLM sangat beragam. Misalnya, image captioning: memberikan deskripsi teks dari gambar. Atau Visual Question Answering (VQA): menjawab pertanyaan tentang gambar yang dilihat. Ada pula model yang bisa membuat gambar dari deskripsi teks (text-to-image generation) atau mencari gambar berdasarkan teks (image-text retrieval). Ringkasnya, VLM menghubungkan dunia visual dan verbal, memungkinkan AI memahami hubungan antara apa yang dilihat dan bagaimana mengekspresikannya lewat kata.
Beberapa teknik utama dalam VLM mengingatkan kita lagi pada cara belajar manusia. Contohnya contrastive learning: model belajar membedakan pasangan gambar-teks yang cocok dan tidak cocok. Misalnya, model ditunjukkan foto kucing dan diberikan dua caption: “Seekor kucing tidur” dan “Sebuah mobil balap merah”. Model belajar mengaitkan pasangan yang benar dan menolak yang salah. Inilah cara kerja model seperti CLIP. CLIP dilatih dengan jutaan pasangan gambar-teks, dan tugas utamanya adalah mencocokkan gambar dengan deskripsi yang benar. Analogi sederhananya, CLIP seperti petugas keamanan bandara terlatih: sangat cepat menentukan apakah sebuah foto wajah cocok dengan nama pemilik wajah.
Selain itu, ada teknik Prefix-LM yang digunakan oleh model seperti SimVLM. Cara kerjanya mirip saat seseorang memberi kita sebagian kalimat dan kita harus menyelesaikannya berdasarkan apa yang kita lihat. Misalnya, jika seseorang melihat foto taman dan berkata, “Di taman ini terlihat…”, kita akan melanjutkan deskripsi secara alami. SimVLM mengambil gambar dan beberapa kata awal (“prefix”) lalu melanjutkan teks sesuai konteks visual itu. Ringkasnya, SimVLM menjadi “sang pencerita sederhana”: mulai menulis kalimat berdasarkan pandangannya terhadap gambar lalu melengkapinya.
Sedangkan model seperti VisualGPT menggunakan cross-attention, mekanisme yang membuat model “memperhatikan” bagian spesifik dari gambar saat menghasilkan teks. VisualGPT menerima representasi gambar dan menggunakan cross-attention untuk menghubungkan detail gambar dengan teks yang dibuat. Keistimewaannya adalah self-resurrecting activation, semacam alarm kecil di jaringan yang mencegah hilangnya informasi gambar selama proses belajar. Analoginya, bayangkan Anda bercerita tentang foto yang dilihat. Setiap kali hampir lupa detail penting—“Eh, warnanya biru!” atau “Oh, itu objek utama di sebelah kanan!”—ada alarm yang membangunkan Anda. Itulah fungsi self-resurrecting activation pada VisualGPT. Hasilnya, VisualGPT menjadi “si seniman AI” yang tidak hanya mendeskripsikan gambar, tapi juga bisa bercerita lebih kreatif dan detail.
Singkatnya, ketiga model ini punya peran berbeda bak tiga temen AI: CLIP si pengecek cepat, SimVLM si pencerita sederhana, dan VisualGPT si seniman kreatif. Meskipun tugasnya beragam, semua VLM ini mirip otak manusia dalam menggabungkan penglihatan dan bahasa. Semuanya menggunakan “mata canggih”—seringkali menggunakan teknologi Vision Transformer (ViT) —sebagai penglihatan mereka. Sebagai contoh, CLIP dan SimVLM memanfaatkan ViT sebagai encoder visual utama, sedangkan VisualGPT fleksibel: dapat pakai CNN biasa atau ViT tergantung kebutuhan. Intinya, VLM menghubungkan dunia visual dengan kata-kata, menjadikan interaksi manusia-mesin lebih alami dan “multimodal”.
Aplikasi dalam Kehidupan Sehari-hari
Teknologi pengenalan ekspresi dan VLM ini punya banyak aplikasi praktis. Misalnya, pengenalan emosi kini bisa diterapkan di kamera pintar dan surveilans. Sebuah aplikasi telekonferensi mungkin bisa membaca ekspresi peserta (senang, terkejut, atau marah) untuk mengukur respon audiens secara real-time. Di bidang kesehatan, AI bisa membantu psikolog atau dokter membaca suasana hati pasien dari ekspresi wajah mereka.
Contoh lain adalah image captioning (pemberian keterangan gambar otomatis). Ini sangat berguna untuk aksesibilitas. Bagi penyandang tunanetra, AI bisa menerjemahkan gambar ke deskripsi suara. Misalnya, jika melihat foto “seekor kucing di sofa”, AI bisa membacakan “Seekor kucing duduk di sofa” sehingga pengguna bisa mendengar isi gambar. Banyak situs web sekarang menggunakan teknologi semacam ini untuk membuat alt-text otomatis pada gambar, yang membantu pembaca layar menguraikan gambar.
Di e-commerce, VLM bisa membuat deskripsi produk otomatis. Cukup unggah foto kaos atau sepatu, lalu AI akan menghasilkan teks deskriptif (“kaos lengan panjang katun berwarna biru”) yang membantu pengunjung toko online memahami produk tanpa perlu menulis penjelasan manual. Manfaat lainnya termasuk pencarian visual (mencari gambar atau produk dengan memasukkan deskripsi teks) serta konten kreatif seperti pembuatan cerita atau ilustrasi otomatis berdasarkan skenario yang kita bayangkan. Pada akhirnya, visi-language AI menjembatani mata dan kata, memperkaya banyak bidang — dari interaksi harian dengan gadget hingga dunia medis atau hiburan.
Otak dan Mesin Sama-sama Belajar Melihat
Pada akhirnya, AI dalam pengenalan ekspresi wajah tak sekadar “memindai” pixel. Ia meniru cara kerja otak manusia: memecah wajah menjadi banyak sinyal kecil (dalam Vision Transformer disebut patch, namun dalam Semantik transformer sinyak kecil ini disebut token), kemudian mengolahnya lewat ribuan “neuron visual digital”, lalu mengambil kesimpulan dari perubahan antar-citra. Pertahankan 1280 neuron visual bukanlah pemborosan resources parameter; justru memberikan AI ketajaman ekstra—mirip otak manusia yang butuh banyak neuron untuk mengenali kerutan dan senyum yang sangat halus.
Dengan kata sederhana: AI membutuhkan 1280 “neuron visual” karena wajah manusia menyimpan terlalu banyak cerita untuk dipahami hanya dengan sedikit indera penglihatan. Di titik ini, AI bukan berusaha menggantikan otak kita, melainkan belajar memahami hal yang selama ini kita lakukan dengan sangat baik: membaca wajah dan mengenali emosi. Semakin cara kerja AI mendekati cara kerja otak, semakin pintar pula AI dalam memahami kita dan dunia sekitar.
– AO –
Tangerang Selatan, 26 November 2025
Sumber: meringkas artikel “Understanding vision-language models and their applications” dan menuliskan kembali dengan analogi cara kerja otak biologis.
https://www.ultralytics.com/blog/understanding-vision-language-models-and-their-applications