– Arief Prihantoro –
Kecerdasan Buatan dan Otak Manusia: Mengurai Cara Kerja AI Lewat Analogi Otak Biologis
Pernyataan Dr. Ryu Hasan, seperti dalam video terlampir dan saat ini sedang viral, sangat menohok masyarakat Indonesia: kenapa kini rata-rata score kecerdasan Masyarakat Indonesia menurun drastis selama beberapa dekade, bahkan kini rata-rata mendekati score IQ Gorila. Tulisan ini mencoba menjelaskan dengan perspektif analogi kecerdasan buatan atau akal imitasi (AI).
Dalam beberapa tahun terakhir, publik semakin akrab dengan teknologi Generative AI. Kita mengenal nama-nama seperti Gemini, DeepSeek, ChatGPT, Claude, Gema-3, dan banyak lainnya. Bayangkan Anda sedang bertanya kepada ChatGPT tentang resep masakan atau esai kuliah—mesin tersebut seolah “berpikir” seperti manusia. Padahal sesungguhnya, kecerdasan buatan (AI) bekerja sangat berbeda dengan otak manusia. Dalam AI, kata cerdas lebih merujuk pada potensi bawaan (yang ditentukan oleh arsitektur model) daripada kecerdasan nyata. Sebuah model AI disebut “cerdas” jika struktur dan parameternya cukup kompleks untuk mengerti pola, tetapi jika tidak dilatih maka ia takkan tahu apa-apa. Sederhananya, AI ibarat otak yang belum belajar apa-apa: arsitekturnya memberi potensi, namun kecerdasannya baru muncul setelah proses belajar dan latihan .
Pada manusia kita biasa bilang ada orang cerdas, pintar, dan pandai. Di dunia AI istilah ini pun digunakan, namun maknanya berbeda-beda. Karena itu, kita harus memahaminya dengan analogi seorang siswa yang sedang menjalani proses belajar di sekolah.
Tiap model memiliki kemampuan yang berbeda, dan sering kali kita mendengar istilah seperti “model ini lebih pintar karena parameternya lebih banyak”. Ada pula yang membandingkan ukuran besarnya parameter model seolah-olah itu adalah IQ sebuah mesin AI yang sesungguhnya. Angapan bahwa “semakin banyak parameter, semakin cerdas AI” adalah keliru. Untuk memahami mengapa demikian, kita harus kembali kepada sumber inspirasi awal kecerdasan buatan: otak biologis.
Cerdas, Pintar, dan Pandai: Analogi di Dunia AI
Di sekolah, seorang siswa bisa dikatakan cerdas apabila ia memiliki otak yang potensial memahami berbagai hal, meski belum sempat belajar pelajaran tertentu. Demikian pula AI “cerdas” artinya model itu punya arsitektur dan jumlah parameter yang cukup untuk memahami pola dalam data. Contohnya, arsitektur Transformer atau CNN yang besar memungkinkan AI punya kapasitas merajut relasi antar kata atau antar fitur visual lebih banyak. Namun, cerdas saja belum cukup – tanpa proses belajar ia tidak akan berguna. Ini seperti anak yang genetiknya cerdas untuk matematika, tapi jika tidak pernah mengerjakan soal atau membaca buku, ia tetap belum pintar.
Setelah belajar dari data (analogi: membaca buku atau mengerjakan latihan), barulah AI menjadi ‘pintar‘. Istilah pintar di sini berarti model telah menyerap banyak pengetahuan dari data sehingga mampu menjawab soal-soal serupa. Proses ini terjadi saat algoritma optimasi (misalnya gradient descent) memperbarui bobot model berdasarkan kesalahan yang dihitung. Jika AI sudah ‘pandai‘, ia berarti memiliki kemahiran dalam mengerjakan tugas tertentu berkat latihan berulang-ulang.
Analogi sederhananya: berlatih 1000 soal membuat otak memahami pola, bukan sekadar latihan coba-coba tanpa ada pemahaman. Singkatnya, cerdas adalah potensi bawaan (arsitektur, jumlah neuron, jumlah sinapsis), belajar (learning) adalah proses internal memperbaiki pemahaman model, dan berlatih (training) adalah aktivitas mengerjakan banyak contoh agar pemahaman itu tumbuh. Tanpa arsitektur yang “cerdas”, proses belajar sulit efektif. Dan tanpa latihan, AI tidak akan pernah benar-benar pandai, analoginya seperti halnya seorang siswa tanpa latihan, kecerdasan akademis dia tak berkembang.
Banyaknya Neuron Tidak Menentukan Kecerdasan
Ikan Paus memiliki jumlah neuron lebih banyak daripada manusia. Secara kasar, otak paus memiliki massa yang berlipat-lipat dibanding otak manusia. Jika kecerdasan hanya dihitung dari “berapa banyak neuron”, seharusnya paus jauh lebih jenius daripada manusia.
Namun apakah paus lebih cerdas daripada manusia? Jawabannya: tidak secara komprehensif.
Paus memang unggul dalam kecerdasan tertentu—misalnya kecerdasan akustik dan spasial—tetapi tidak dalam kecerdasan umum. Paus memiliki jumlah neuron jauh lebih banyak daripada manusia dewasa, tetapi manusia memiliki keunggulan dalam penalaran simbolik, perencanaan, kemampuan abstraksi dan logika tingkat tinggi, serta kapasitas pembelajaran yang tak dimiliki paus.
Artinya: jumlah neuron tidak otomatis berkorelasi dengan kecerdasan. Jumlah neuron bukan ukuran tunggal kecerdasan.
Bayi Lebih Banyak Sinapsis dari Orang Dewasa — Tetapi Tidak Lebih Cerdas
Fenomena lain yang menarik adalah perkembangan otak manusia. Bayi memiliki jumlah sinapsis lebih banyak daripada orang dewasa. Namun kita tidak menyebut bayi sebagai makhluk tercerdas di bumi.
Mengapa demikian?
Karena pada masa tumbuh kembang, otak manusia melakukan proses yang disebut synaptic pruning. Istilah lain dari pruning adalah : synaptic elimination, neural pruning, use-it-or-lose-it mechanism. Dalam proses ini, pruning terjadi ketika sinapsis yang sering digunakan diperkuat, sedangkan sinapsis yang jarang digunakan dilemahkan, bahkan dihilangkan. Proses ini ibarat “merapikan kabel” agar jalur sinyal lebih efisien, cepat, dan tepat sasaran. Analogi ini mirip dengan konsep parameter freezing dalam AI: “parameter yang jarang digunakan mulai “dibekukan”, sementara parameter yang sering digunakan diperkuat melalui training dan learning”.
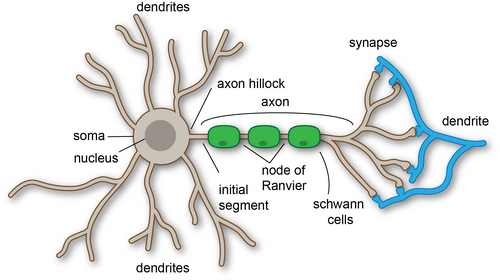
Pruning inilah yang membuat manusia dewasa:
- memiliki lebih sedikit sinapsis dibanding bayi, tetapi
- jauh lebih cerdas, efisien, dan mampu bernalar secara kompleks.
Penting diketahui:
Jumlah sinapsis tidak menentukan kecerdasan. Yang menentukan adalah organisasi dan efisiensinya.
Akhirnya, saat dewasa, jumlah sinapsis memang lebih sedikit, tetapi lebih efisien, lebih terorganisir, dan lebih fungsional — sehingga kecerdasan manusia dapat meningkat dibanding saat masih bayi meskipun jumlah sinapsisnya berkurang sangat signifikan.
Banyak Parameter Tidak Membuat AI Lebih Cerdas
Sama seperti neuron, sinapsis dan dendrit pada otak manusia, dalam AI parameter adalah “konektor” atau “jalur” yang menyimpan pola. Dalam AI modern—khususnya model berbasis Transformer—parameter terdiri dari weight dan bias yang digunakan untuk memproses input dan membuat prediksi.
Seperti sinapsis, parameter hanyalah kapasitas mentah. Satu neuron bisa memiliki banyak sinapsis, sesuai dengan fungsinya. Dan jumlah sinapsis dalam satu neuron dengan neuron lainnya tidak selalu sama. Tetapi kapasitas atau “banyak ruang” tidak berarti “memiliki kemampuan pemahaman yang lebih baik”. Dia hanya memiliki kapasitas penyimpanan data lebih besar namun tidak memiliki feature atau fungsi untuk pengolahan data secara neural.
Analoginya sangat sederhana:
- Hard disk 10 TB tidak otomatis lebih “pintar” dari flashdisk 64 GB. Jika Hard disk 10 TB hanya berisi file-file sampah yang tidak ada manfaatnya.
- Rumah dengan 20 kamar tidak otomatis lebih nyaman daripada rumah dengan 5 kamar.
- Otak bayi dan otak paus besar secara kapasitas, tetapi tidak membuat keduanya lebih cerdas dari manusia dewasa.
Parameter hanya menyediakan ruang untuk menyimpan pola, bukan kemampuan untuk memahaminya. Seperti sinapsis, parameter menyimpan pola seperti:
- struktur bahasa
- hubungan antar kata
- logika dasar
- pola matematis
- pengetahuan faktual
- gaya menjawab
- preferensi bahasa
Tetapi pola ini tidak otomatis muncul hanya karena parameternya banyak. Ia harus dipelajari terlebih dahulu. Seperti halnya seorang bayi begitu lahir sudah dibekali modal dasar arsitektur neuron dan sinapsis yang jauh lebih banyak dibanding manusia dewasa. Namun sinapsis yg menjadi bawaan si bayi sejak dia dilahirkan belum terorganisasi dengan baik, sehingga komunikasi neurotransmiter antara sinapsis dengan dendrit pada neuron yg berdekatan tidak efisien sehingga tidak bekerja secara fungsional. Neuronnya memiliki banyak sinapsis namun sinapsis tersebut belum bisa bekerja dengan baik sesuai fungsinya. Tidak semua sinapsis bawaan lahir akan dilatih selama proses pertumbuhan. Sama halnya tidak semua parameter dalam dataset AI akan dilatih selama proses training and learning.
Dan di sinilah kesalahpahaman terbesar sering terjadi.
Anatomi Otak AI: Arsitektur, Parameter, dan Pengalaman
Bagaimana otak AI tersusun? Ada tiga komponen penting: arsitektur, parameter, dan data (dataset). Kita bisa membuat perumpamaan biologis untuk memudahkan. Bayangkan parameter (bobot) dalam jaringan saraf tiruan tersebut seperti sinapsis di otak biologis. Arsitektur jaringan (misalnya Transformer, CNN, LSTM) adalah “bentuk otaknya” – bisa diibaratkan susunan neuron biologis tiruan serta jalur koneksinya. Data yang dilatih ibarat pengalaman yang dipelajari otak. Ada pengalaman bawaan (dataset awal), ada pengalaman hasil dari berlatih lewat proses kehidupan (model hasil latih).
- Arsitektur = “bentuk otak” AI. Susunan layer dan koneksi menentukan kemampuan awal model, mirip struktur korteks otak manusia yang berbeda-beda untuk fungsi yang berbeda. Misalnya, arsitektur CNN cocok untuk visi computer (Computer Vision), sedangkan Transformer unggul di bahasa (kecerdasan linguistik). Arsitektur ini memberi potensi intrinsik kepada AI.
- Parameter = sinapsis otak. Setiap bobot di jaringan adalah jalur koneksi yang menguatkan atau melemahkan sinyal, persis seperti sinapsis menghubungkan neuron biologis lewat komunikasi neurotransmiter ke dendrit. Semakin banyak parameter artinya model punya lebih banyak “sinapsis” untuk menyimpan pola dan pengetahuan. Namun ingat, sinapsis tanpa pengorganisasian (baik pengorganisasian awal ataupun lewat latihan) tidak menjamin kecerdasan.
- Data = pengalaman hidup. Pengalaman yang kaya dan beragam dibutuhkan agar pola yang dapat menghubungkan korelasi antar data yang disimpan di neuron dapat bermakna. AI yang hanya dilatih dengan sedikit data atau data tidak relevan justru “bingung” dan bisa overfitting.
- Training & Learning = proses berlatih dan belajar. Inilah saat AI mengubah bobot (analoginya dengan sinapsis) berdasarkan data, seperti otak yang memperkuat atau melemahkan jalur saraf setelah belajar .
Dengan analogi tersebut, kecerdasan AI muncul dari pola yang terbentuk di antara sinapsis-sinapsisnya. Banyaknya parameter memberi kapasitas penyimpanan memori yang besar (analog hard disk besar), tetapi “banyak ruang” bukanlah kecerdasan. Sama seperti otak manusia: bayi lahir dengan sekitar 100 triliun sinapsis tetapi belum cerdas, sedangkan orang dewasa memiliki lebih sedikit sinapsis (karena penyempitan sinaptik), namun pola koneksinya yang efisien membuatnya jauh lebih cerdas. Begitu pula model AI dengan parameter besar tanpa organisasi latihan yang baik tidak akan unggul; sebaliknya, model kecil yang efisien dan dilatih optimal bisa mengungguli model besar. Secara sederhana dapat dikatakan: Arsitektur+parameter+training = kecerdasan AI.
Arsitektur dan banyak parameter memberi potensi (“benih” otak AI), sedangkan data berkualitas dan proses pelatihan mengubahnya menjadi kemampuan nyata.
Belajar Layaknya Murid di Sekolah
Agar lebih nyata, mari lihat proses pelatihan AI seperti proses belajar murid di sekolah. Bayangkan seorang siswa berlatih matematika: ia mengerjakan banyak soal, memeriksa jawabannya, lalu memahami kesalahan untuk belajar konsep baru. AI bekerja serupa:
- Persiapan (pre-processing). Seperti murid membuka buku dan menyiapkan alat tulis, proses mengumpulkan dan mengolah data (data preparation) dilakukan sebelum “berlatih”. Data mentah (gambar, teks, video) dibersihkan, diberi label, dan dibagi ke dalam batch untuk pelatihan. Pada tahap ini otak AI masih kosong pengalaman nyata, belum ada yang dipelajari.
- Feedforward (Berlatih). AI menerima satu batch data dan mencoba “menjawab” berdasarkan kondisi bobot saat ini. Ibaratnya seorang bayi baru lahir diberi payudara ibunya, didekatkan pada putingnya, dia akan mencoba-coba secara naluriah (cerdas bawaan atau parameter bawaan kalau dalam konteks AI) untuk menghisap-hisap puting tersebut. Awalnya dia tidak tahu posisi netek yang nyaman buat dirinya. Maka kadang puting tersebut terlepas dari mulutnya dan dia menangis (analogi dengan proses loss dalam training AI). Dia murni coba-coba. Ini latihan murni – model hanya memproses input ke output tanpa perubahan internal. Analogi: murid mengerjakan soal latihan tanpa langsung tahu apakah benar atau salah. Selama feedforward, model menghasilkan prediksi (misal menjawab soal) dan menghitung loss (kesalahan).
- Memeriksa Jawaban (Evaluasi Sederhana). Mirip murid yang melihat kunci jawaban setelah mengerjakan, AI membandingkan prediksi dengan jawaban sebenarnya. Dalam konteks AI, jawaban sebenarnya tersebut berupa dataset yang dikategorikan sebagai data tes atau data uji saat splitting dataset. Sedangkan validitas soal yang diberikan dalam ujian dapat diibaratkan sebagai soal yang sudah tervalidasi, apakah benar soal tersebut soal yang valid sesuai konteks, misal belajar matematika namun soal yang diberikan adalah soal bahasa, ini soal yang tidak valid sehingga memungkinkan jawaban yang juga tidak valid. Loss yang didapat menunjukkan berapa “salah” model dalam setiap soal. Tahap ini masih termasuk aktivitas latihan (model sedang diuji), tapi belum terjadi belajar internal.
- Backpropagation (Belajar). Setelah tahu kesalahan selama proses pelatihan, inilah saatnya belajar. AI menghitung gradien – seberapa besar setiap bobot (weight) berkontribusi terhadap error – dan menggunakan optimizer untuk mengupdate bobot. Dan seberapa besar deviasi kesalahannya (atau bias paramater kalau dalam AI). Ini seperti siswa membaca koreksi guru: “Oh, ternyata saya salah menggunakan rumus” dan kemudian memahami konsep yang benar. Pada tahap inilah pemahaman baru terjadi; bobot model berubah, ditambah dengan toleransi bias, kemudian pola pengetahuan baru tersimpan.
- Ulangi Banyak Kali. Langkah feedforward dan backpropagation diulang untuk banyak batch data dan dalam banyak epoch (siklus penuh data). Setiap kali “mengerjakan soal” (feedforward) dan “melihat kunci jawaban” (backprop), model sedikit demi sedikit menjadi lebih pintar. Tanpa latihan (batch) tidak ada kesempatan untuk meningkatkan kepandaian, dan tanpa proses belajar (update bobot), latihan tidak akan membuat model lebih pintar. Pandai namun tidak pintar.
Secara natural, makhluk biologi akan menjalani proses coba-coba (latihan) dulu sebelum kemudian belajar. Demikian pula dengan AI. Tahap awal setelah pre processing adalah feed forward. Selama feed forward pertama inilah model berlatih tahap awal dan kemudian dilanjut dengan tahap evaluasi dan back propagation dan kemudian latihan kembali. Dalam proses evaluasi model telah belajar wawasan baru. Proses ini terjadi secara berulang-ulang (feedback loop), hingga proses training selesai.
Perbedaan kunci: latihan (training) adalah aktivitas eksternal mengerjakan banyak data, sedangkan belajar (learning) adalah proses internal mengubah bobot. Semua proses di atas harus berulang agar AI bisa menggeneralisasi dan meningkatkan kemampuannya .
Feedforward dan Backpropagation: Mekanisme “Berpikir” AI
Dalam analogi sekolah tadi, Feedforward adalah saat murid mencoba menjawab soal (tanpa segera mengoreksi jawabannya). Di sinilah AI melakukan perhitungan maju: input dikalikan bobot, melewati fungsi aktivasi, lalu menghasilkan prediksi. Tidak ada perubahan bobot di sini – AI hanya menggunakan ingatan awal (parameter) yang sudah ada untuk memproduksi jawaban.
Sebaliknya, Backpropagation adalah saat murid memeriksa soal dengan buku kunci dan menyadari mana yang salah. AI menghitung berapa besar kesalahan (loss), lalu menyebarkan (back-propagate) sinyal error itu ke belakang melalui lapisan demi lapisan (layer) neuron. Tiap bobot dikoreksi berdasarkan perannya dalam kesalahan, dan optimizer mengatur seberapa besar koreksi dilakukan. Inilah inti belajar – model memperbaiki “cara berpikir” agar prediksi berikutnya lebih akurat.
Secara ringkas:
- Feedforward = AI berlatih memprediksi (menghasilkan jawaban).
- Backpropagation = AI belajar (memperbarui bobot).
Tanpa feedforward, model tidak tahu jawabannya; tanpa backpropagation, model tidak akan pernah lebih pintar. Keduanya harus berulang-ulang agar kecerdasan AI tumbuh. Inilah mengapa algoritma backpropagation dipandang sebagai “belajar” utama dalam jaringan saraf tiruan.
Kenapa Model Besar Tidak Selalu Lebih Pintar
Sering timbul anggapan: “makin besar model AI (parameternya), maka model tersebut dikatakan makin pintar.” Anggapan ini keliru. Model besar memang punya kapasitas mentah lebih besar (seperti hard disk 10TB versus 1TB) untuk menyimpan pola, tapi banyak faktor lain yang memengaruhi seberapa cerdas ia sebenarnya:
- Arsitektur yang tepat: Dua model dengan jumlah parameter sama bisa memiliki performa sangat berbeda jika arsitekturnya tidak cocok. Misalnya, arsitektur yang salah desain bisa membuat model “besar” malah tidak efisien.
- Kualitas dan Kuantitas Data: Data pelatihan yang sedikit atau berantakan justru bikin model besar kebingungan (overfitting). Sebaliknya, model yang “kecil” namun dilatih dengan data bersih dan kaya ragam bisa lebih unggul.
- Metode Pelatihan: Cara pelatihan (optimizer, learning rate, batch size, regularisasi, dsb.) sangat memengaruhi hasil. Optimasi yang kurang pas, atau strategi pelatihan yang buruk, membuat kemampuan model tidak berkembang meski parameter banyak.
- Tujuan Pelatihan: Model 10 miliar parameter yang dilatih untuk tugas berbeda (bahasa vs gambar vs kode) akan punya kecerdasan yang berbeda pula. Banyak parameter tidak berarti memiliki “kecerdasan universal”; ia tergantung apa yang dipelajarinya.
Bukti empiris pun menunjukkan banyak model kecil malah mengalahkan model yang lebih besar. Contohnya, model ukuran 3–7 miliar parameter sering mengungguli model 10–15 miliar dalam penalaran. Model TinyLLM yang cuma 1,6 miliar parameter bahkan mengalahkan model yang jauh lebih besar dalam tes logika dan reasoning.
Mengapa?
Karena model kecil tersebut dilatih dengan dataset yang bersih, arsitektur efisien, dan teknik pelatihan modern yang lebih matang. Akhirnya, banyak parameter hanyalah kapasitas penyimpanan pola, bukan kecerdasan. Model besar bisa jadi “otak besar” namun kosong jika tidak terlatih dengan baik. Sama seperti otak manusia: manusia dewasa punya lebih sedikit sinapsis daripada bayi baru lahir (karena terjadi penyempitan sinaptik), tetapi manusia dewasa justru lebih cerdas karena sinapsisnya yang tersisa telah diorganisasi dengan lebih baik lewat pengalaman hidup. Otak bayi tersebut memang “otak besar” namun “otak kosong” pengalaman. Dalam AI, model kecil yang “dipangkas sinapsisnya” dan dilatih optimal dapat jauh lebih pintar daripada model raksasa yang belum terlatih dengan baik.
Optimizer: Mekanisme Belajar dalam Otak AI
Jika bobot dan data adalah memori otak AI, maka optimizer berperan seperti mekanisme pembelajaran otak itu sendiri, strategi model dalam berlatih dan belajar. Optimizer adalah algoritma yang membaca sinyal kesalahan (gradien) dan mengatur bagaimana bobot diperbarui. Secara analogi:
- Bobot = ingatan otak. Sinyal (input) diproses dengan bobot, menghasilkan ide atau prediksi.
- Gradien = sinyal kesalahan. Saat prediksi meleset, gradien menunjukkan seberapa besar kesalahan dan arah kesalahannya, seperti guru berenang yang menunjukkan di mana murid salah arah dan salah pola gerakan lantas ditunjukkan arah yang benar dan gerakan yang benarnya seperti apa.
- Optimizer = mesin belajar. Ia mengambil gradien ini untuk memutuskan seberapa banyak dan kemana harus mengubah bobot. Tanpa optimizer, neural network tidak tahu bagaimana “belajar” dari kesalahan. Ibaratnya seorang murid tidak paham strategi belajar untuk jenis mata pelajaran tertentu. Setiap mata pelajaran memiliki strategi pembelajaran yang berbeda-beda, tidak bisa dipukul rata.
Ibarat mendaki gunung, gradien bagai kemiringan lereng, learning rate menentukan langkah kaki, sedangkan optimizer adalah strategi pendakian agar tidak terperosok, atau strategi menuruni gunung agar lebih cepat namun efisien. Ada berbagai jenis optimizer (SGD, Adam, dll.), namun prinsipnya sama: memandu AI menurunkan lanskap loss yang tak rata agar menuju titik terendah (kinerja terbaik). Kesimpulannya, optimizer adalah bagian otak yang benar-benar melakukan “pembelajaran”.
Tanpa optimizer, proses training hanya berputar tanpa perubahan; bobot tidak bergeser, model tidak menjadi pintar. Dengan optimizer, AI secara perlahan mengoreksi memori mereka sendiri berdasarkan “saran” gradien, mirip murid yang memperbaiki pemahaman setelah melihat hasil latihan lalu mendapat saran dari gurunya bagaimana cara belajar yang lebih baik sesuai mata pelajaran yang sedang dia pelajari.
Gambar tabel berikut ini contoh arsitektur sederhana dari sebuah model AI Computer Vision. Dia memiliki parameter (weight+bias) bawaan arsitektur sebanyak 3 juta (sesuai dataset awal yang diberikan), namun yang dilatih hanya 750 ribuan. Yang 2,25 juta di-freeze. Sehingga yang akan berkembang lebih baik selama proses pelatihan adalah parameter yang berjumlah 750 ribuan. Sementara yg 2,25 juta parameter tidak mengalami perubahan (perkembangan) setelah proses pelatihan berakhir. Dari yang 750 parameter, ada parameter yang berkembang lebih baik dan ada yang semakin lemah, karena bisa jadi sejak dari proses desain arsitektur secara bawaan model tersebut keliru dalam pre processing atau kurang akurat dalam menentukan jenis/nilai parameternya.
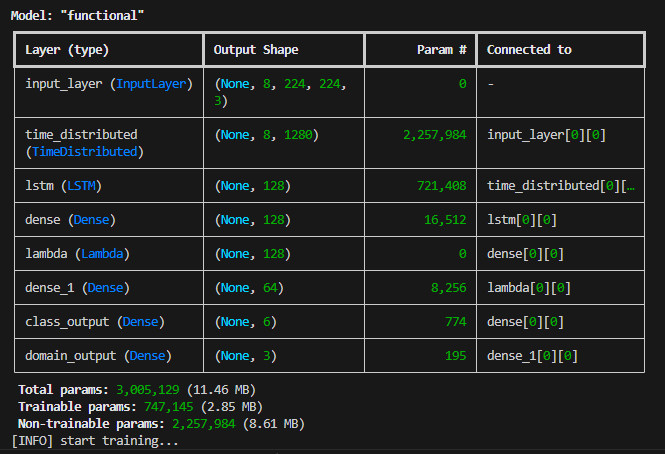
Secara ringkasnya, Bagaimana AI Sebenarnya “Belajar” dan “Berlatih”?
A. Berlatih (Training): Aktivitas Eksternal
Berlatih adalah aktivitas ketika AI mengerjakan banyak contoh data berulang-ulang.
Contoh:
model “melihat” ribuan kalimat dan mencoba memprediksi kata berikutnya.
Saat berlatih, AI melakukan feedforward:
- input → proses → output
- belum tahu benar atau salah
- belum mengubah bobot
Ini sama seperti murid mengerjakan soal latihan tanpa langsung melihat kunci jawaban.
Berlatih bukan belajar.
Ini hanyalah aktivitas mencoba-coba pengetahuan baru hingga terbentur atau menemukan kesalahan, atau justru pemahaman baru yang telah diperolehnya ternyata menghasilkan nilai prediksi yang benar.
B. Belajar (Learning): Proses Internal
Belajar terjadi saat model menerima umpan balik dari kesalahan.
Ketika outputnya salah, model menghitung seberapa besar kesalahan tersebut (loss).
Lalu masuk tahap backpropagation:
- menghitung kontribusi tiap parameter
- memperbarui parameter
- memperbaiki pemahaman
Ini analogi dari murid melihat kunci jawaban dan memahami kesalahannya.
Belajar = pembaruan internal yang menghasilkan wawasan baru.
C. Siklus Sibernetika: Feedback Loop
AI bekerja melalui loop berulang:
- Berlatih → feedforward
- Mengukur kesalahan
- Belajar → backpropagation
- Perbaikan parameter
- Berlatih lagi dengan pemahaman baru
- Belajar lagi
- Berlatih lagi
- Belajar lagi
- berlatih lagi
- dst, hingga akhir proses pelatihan sesuai yang telah ditetapkan lewat nilai epoch dan batch
Siklus tak berhenti ini mirip dengan:
- berlatih bermain gitar
- berlatih berenang
- berlatih matematika
- latihan bertarung di olahraga bela diri
Wawasan dari error—bukan latihannya—yang membuat kita lebih pintar.
Demikian pula dengan AI.
Feedforward dan Backpropagation: Mekanisme “Berpikir” AI
Lebih rinci:
Feedforward = mencoba menjawab
Analogi: murid mengerjakan soal.
Model:
- menerima input
- menghitung hasil
- mengeluarkan prediksi
- belum mengubah bobot
Backpropagation = memahami kesalahan
Analogi: murid melihat koreksi guru.
Model:
- menghitung kesalahan
- menelusuri kontribusi setiap bobot
- memperbarui bobot
- memahami pola baru
Inilah proses belajar.
Optimizer: Bagian “Otak” yang Mengatur Cara Belajar
Optimizer adalah algoritma yang memandu bagaimana AI memperbaiki dirinya.
Ibarat:
- strategi guru mengajar
- metode belajar efektif
- cara memecahkan soal dengan efisien
Optimizer memilih:
- seberapa banyak bobot harus diubah
- arah perubahannya
- seberapa cepat perubahan dilakukan
Tanpa optimizer, AI akan berlatih tanpa pernah belajar.
Jadi Mengapa Model Besar Tidak Selalu Lebih Pintar?
Secara ringkas ada empat alasan besar mengapa AI besar tidak otomatis lebih cerdas.
A. Arsitektur Buruk → Parameter Tidak Efisien
Dua model dengan jumlah parameter sama dapat menghasilkan kecerdasan yang jauh berbeda jika arsitekturnya tidak baik.
Dalam anatomi otak manusia, ini seperti membandingkan otak dengan struktur kacau versus otak dengan struktur rapi. Koneksi yang berantakan tidak berarti lebih pintar meski jumlah sinapsisnya lebih banyak.
B. Data Tidak Memadai → Model Besar Bisa “Bingung”
Model besar memerlukan data berkualitas tinggi.
Jika data sedikit:
→ Model besar justru overfitting.
Jika data buruk:
→ Parameter akan menyimpan banyak pola yang salah.
Jika data berantakan:
→ Kapasitas besar tidak ada gunanya.
C. Cara Pelatihan Tidak Optimal
Faktor pelatihan sangat menentukan kecerdasan model.
Komponen penting:
- optimizer
- learning rate
- batch size
- regularization
- strategi fine-tuning
- kondisi stabilitas pelatihan
D. Tujuan Pelatihan Berbeda
Model besar untuk:
- visi komputer
- bahasa manusia
- analisis audio
- pemrograman
- penalaran matematika
semuanya dilatih dengan dataset berbeda dan tujuan berbeda.
Mereka tidak bisa disamakan kecerdasannya hanya karena jumlah parameternya sama.
Fakta Empiris: Model Kecil Sering Mengalahkan Model Besar
Dalam dunia AI modern, kita melihat fenomena menarik:
- Mistral 7B (Bilion/miliar parameter) mengalahkan model 13–30B.
- Phi-3 (3–7B) mengungguli banyak model 10–15B.
- TinyLLM 1.6B mengalahkan model raksasa dalam reasoning.
Mengapa hal ini bisa terjadi?
Karena:
✔ dataset lebih bersih
✔ arsitektur efisien
✔ kurasi data ketat
✔ teknik training lebih matang
✔ regularisasi baik
✔ tokenisasi optimal
Efisiensi mengalahkan ukuran.
Organisasi mengalahkan kuantitas.
Sama seperti otak bayi vs otak dewasa.
Kesalahan kecil dalam konfigurasi dan pengorganisasian ini bisa membuat model besar menghasilkan kecerdasan rendah—ibarat siswa cerdas namun selalu keliru dalam melakukan latihan berulang dan kemudian tidak mempelajari pola kesalahan. Bisa dikatakan dia keliru dalam metode belajar. Akibatnya, sekalipun dia cerdas secara bawaan namun tidak menjamin dia pintar dan pandai setelah berlatih dan belajar. Misal karena keliru mencari guru yang bisa membimbingnya dengan baik.
Jadi cerdas bukan jaminan bahwa dia pasti pintar dan pasti pandai. Dalam otak biologis, kuantifikasi ukuran kecerdasan bisa dilihat dari score IQ. Sementara kuantifikasi kepintaran bisa dilihat dari nilai raport atau IPK. Sedangkan kuantifikasi nilai kepandaian bisa dilihat dari nilai sertifikasi hasil pelatihan yang dia ikuti. Score IQ seorang mahasiswa nilainya tinggi tidak menjamin nilai IPKnya juga tinggi, jika dia tidak pernah belajar.
Dari ketiga nilai kuantifikasi tersebut kita bisa mengatakan bahwa cerdas berbeda dengan pintar dan pandai. Demikian pula halnya dalam dunia kecerdasan buatan. Smartphone disebut sebagai telpon pintar, karena fitur-fitur bawaannya yang bersifat rigid, tidak adaptif seperti arsitektur neural. Dia tidak bisa disebut sebagai telpon cerdas karena dia tidak memiliki arsitektur neuron tiruan yang memiliki kemampuan berlatih dan belajar. Namun jika secara embedded dia dibikin dengan arsitektur neural pada sistem bawaannya, misal ditanamkan pada chipnya atau pada ROMnya, maka dia bisa disebut sebagai Intelligent Phone. Saat ini mungkin belum ada telpon jenis ini. Yang ada adalah Smartphone konvensional yang kemudian diinstal dengan mesin kecerdasan buatan. Mesin kecerdasan tersebut bukan bawaan dari smartphone ketika smartphone tersebut didesain arsitekturnya saat masih dalam proses fabrikasi. Mesin telpon tersebut bukan mesin cerdas, tetapi mesin pintar (smartphone) dengan banyak fitur dan kemampuan menyimpan data, namun tidak memiliki kemampuan bawaan untuk mengolah datanya lewat berlatih dan belajar. Dia juga tidak disebut sebagai telpon pandai, karena tidak memiliki ketrampilan dalam menyelesaikan persoalan-persoalan praktis yang diberikan kepadanya.
Analogi pintar dan pandai
Seorang komentator sepakbola bisa jadi dia pintar menganalisa pertandingan sepak bola. Dia wawasannya luas tentang permainan sepakbola, karena dia memiliki latar belakang Pendidikan Kejuruan Olah Raga. Namun jika dia disuruh terjun ke lapangan belum tentu dia pandai bermain sepakbola, jika dia memang bukan seorang pemain sepakbola yang terlatih. Sebaliknya, seorang pemain sepakbola yang terlatih juga belum tentu bisa menganalisa pertandingan sepakbola jika dia tidak pernah belajar tentang teori permainan sepakbola dan tidak pernah belajar dari pola permainan selama dia berlatih. Namun jika dia belajar dia juga bisa menganalisa secara komprehensif seperti seorang komentator sepakbola. Dalam konteks tersebut, sang komentator disebut pintar sepakbola, bukan pandai sepakbola (kita sering mengistilahkan pintar ngomong tapi belum tentu bisa praktek). Sedangkan sang pemain sepakbola disebut pandai sepakbola, bukan pintar sepakbola jika dia tidak memiliki wawasan ilmu tentang persepakbolaan. Dia bisa bermain sepakbola dengan baik, mahir menggocek bola, namun belum tentu menguasai taktik dan strategi permainan sepakbola.
Contoh lain seorang pandai besi. Seseorang disebut pandai besi karena dia pandai mengolah/menempa besi mentah menjadi bermacam perkakas dari besi. Namun kalau dia diminta menjelaskan tentang ilmu fisika material atau kimia material tentang besi bisa jadi dia tidak bisa menjelaskannya karena dia tidak paham ilmunya. Dia selama ini hanya berlatih menempa besi, tidak pernah belajar tentang ilmu material besi. Maka dia disebut Pandai Besi, karena terampil menempa besi, bukan Pintar Besi. Ketika kemudian dia belajar tentang ilmu fisika material dan kimia material besi maka dia bisa disebut Pintar Besi atau orang yang memiliki ilmu tentang material (besi). Dalam konteks AI, model yang terampil dalam menjawab pertanyaan atau menyelesaikan banyak persoalan disebut sebagai model yang pandai. Dan karena wawasannya luas maka dia disebut model yang pintar. Namun secara bawaan (arsitektur neural) dia disebut sebagai model yang cerdas. Jadi, Cerdas, pintar dan pandai adalah tiga hal yang berbeda. Cerdas faktor utamanya adalah bawaan arsitekturnya, pintar adalah hasil dari proses belajar dan pandai adalah hasil dari proses berlatih.
Parameter (Weight + Bias) = Sinapsis, Kecerdasan = Pola Terorganisasi/Terdistribusi
Untuk memudahkan pemahaman, berikut padanannya dengan meringkas penjelasan sebelumnya:
- Parameter = sinapsis. Banyak parameter = kapasitas penyimpanan ingatan besar
- Arsitektur = struktur otak
- Data = pengalaman
- Training = berlatih
- Error = menyediakan wawasan baru
- Learning = menyerap wawasan baru
- Kecerdasan = pola dalam parameter yang terdistribusi di jaringan. Kecerdasan = kualitas pengorganisasian pola, bukan jumlah parameter
- Backpropagation = belajar dari kesalahan
- Optimizer = menyediakan strategi belajar
- Reasoning = koordinasi pola interaksi antar sinapsis
Dengan cara pandang ini mudah dipahami bahwa:
- Banyak sinapsis tanpa organisasi yang baik dan efisien → tidak cerdas
- Sedikit sinapsis yang terlatih baik → bisa sangat pintar
Ini berlaku baik pada manusia maupun pada AI. Seperti manusia:
• Bayi punya banyak sinapsis → tidak cerdas
• Dewasa punya lebih sedikit sinapsis → jauh lebih cerdas
Karena terjadi pruning serta penguatan jalur penting antar sinapsis dengan dendrit.
Arsitektur AI: Bentuk Otaknya
Arsitektur AI adalah desain bagaimana “otaknya” dibangun.
Beberapa arsitektur terkenal:
- CNN
- RNN / LSTM
- Transformer
- Vision Transformer
- Diffusion Models
- Mixture of Experts
Arsitektur menentukan:
- bagaimana informasi mengalir
- bagaimana perhatian (attention) dibagi
- apa yang boleh berkomunikasi dengan siapa
- seberapa dalam lapisan jaringan
- bagaimana pola disimpan
Arsitektur adalah “bentuk otak”, sementara parameter adalah “sinapsis”. Tanpa arsitektur yang baik, parameter tidak berguna.
Hasil akhirnya adalah model yang:
- mampu bernalar
- memahami bahasa
- menjawab pertanyaan
- menyusun argumen
- mengenali pola kompleks
- menghasilkan konten kreatif
Kecerdasan ini bukan muncul karena ukuran, tetapi karena organisasi pola dari sinapsis dan dendrit. Dari Berlatih, AI yang Cerdas menjadi Pintar.
Apakah Banyaknya Parameter Bisa Meningkatkan Kecerdasan?
Jawabannya:
Ya… bila semua syarat berikut terpenuhi:
• arsitektur tepat
• data berkualitas tinggi
• training stabil dan matang
• optimizer baik dan efektif
• tujuan pelatihan benar dan jelas
Model besar cenderung lebih kuat—tetapi tidak otomatis lebih cerdas. Jika semua terpenuhi, model besar cenderung lebih cerdas. Tetapi jumlah parameter bukan faktor tunggal.
Kesimpulan Utama
✘ Banyak parameter ≠ otomatis kecerdasannya
✔ Efisiensi, arsitektur, data dan kualitas training jauh lebih penting
✔ Model kecil bisa mengalahkan model besar jika dilatih lebih baik
✔ AI belajar lewat feedback loop, bukan lewat ukuran model
✔ Baik AI maupun manusia menjadi cerdas karena organisasi pola komunikasi antar neuron, bukan jumlah neuron/sinapsis/parameter
✔ AI mirip otak manusia: yang penting bukan berapa banyak sinapsis, tetapi seberapa efisien ia digunakan
Kecerdasan Bukan Hanya Satu Jenis: Howard Gardner dan Multiple Intelligences
Ketika membicarakan kecerdasan, kita seringkali membayangkannya hanya sebagai “kemampuan berpikir logis”. Padahal, menurut Howard Gardner, seorang psikolog dari Harvard, kecerdasan manusia jauh lebih majemuk. Dalam teorinya yang terkenal, Multiple Intelligences, Gardner menyebutkan bahwa manusia memiliki beragam jenis kecerdasan, diantaranya:
- Kecerdasan Linguistik — kemampuan berbahasa, menulis, memahami kata
- Kecerdasan Logis-Matematis — kemampuan bernalar secara sistematis
- Kecerdasan Visual-Spasial — kemampuan memahami bentuk, pola, dan ruang
- Kecerdasan Kinestetik — kemampuan koordinasi tubuh (kecerdasan motorik)
- Kecerdasan Musikal — kemampuan mengenali ritme, melodi
- Kecerdasan Interpersonal — memahami orang lain (kecerdasan sosial)
- Kecerdasan Intrapersonal — memahami diri sendiri
- Kecerdasan Naturalis — memahami alam, lingkungan
- Kecerdasan Eksistensial (tambahan) — kemampuan memahami makna hidup yang abstrak
Teori ini menegaskan bahwa kecerdasan tidak bisa diukur oleh satu angka atau satu variabel saja, dan bahwa manusia memiliki spektrum kemampuan yang luas dan beragam.
AI Juga Memiliki Beragam Jenis Kecerdasan
Menariknya, konsep Gardner tentang kecerdasan majemuk juga cocok dijadikan analogi untuk AI modern. AI tidak memiliki satu jenis kecerdasan tunggal. Setiap model AI dibangun dan dilatih untuk kecerdasan tertentu, tergantung arsitektur dan data latihnya.
Misalnya:
a. Kecerdasan Linguistik (Natural Language Intelligence)
Dimiliki oleh model-model bahasa seperti:
- GPT (ChatGPT)
- Gemini
- Claude
- LLaMA
Model-model ini menguasai:
- pemahaman teks
- menyusun argumen
- menerjemahkan bahasa
- menjawab pertanyaan
Ini adalah bentuk kecerdasan linguistik ala AI — mirip kecerdasan linguistik pada manusia.
b. Kecerdasan Visual-Spasial (Vision Intelligence)
Dimiliki oleh model seperti:
- CNN (Convolutional Neural Networks)
- Vision Transformer (ViT)
- EfficientNet, ResNet, Swin Transformer, dsb.
Mereka unggul dalam:
- mengenali objek
- memahami gambar
- mendeteksi pola visual
- memahami struktur ruang
Inilah padanan dari kecerdasan visual-spasial pada manusia.
c. Kecerdasan Auditori & Time-Series
Model seperti:
- RNN
- LSTM
- GRU
- Whisper
memiliki kemampuan mengolah audio, ritme, dan sekuens waktu.
Ini mirip dengan kecerdasan musikal atau kinestetik dalam bentuk digital.
d. Kecerdasan Logika & Reasoning
Model reasoning yang dilatih khusus (misalnya DeepSeek-R1 atau Phi-3 reasoning) memiliki kecerdasan mirip logika-matematis pada manusia sehingga bisa menyelesaikan persoalan-persoalan rumit dalam perhitungan matematis. Misal diminta menghitung persoalan matematika kuantum.
Dengan demikian, AI tidak memiliki kecerdasan universal, tetapi memiliki jenis kecerdasan yang berbeda-beda, tergantung bagaimana arsitekturnya dirancang dan jenis data apa yang mengajarinya.
Sama seperti manusia, kecerdasan AI adalah spektrum, bukan satu variabel angka tunggal.
Kecerdasan Manusia Indonesia Menurun Selama Beberapa Dekade? – Perspektif Dr. Ryu Hasan –
Kembali ke statementnya Dr. Ryu Hasan di awal tulisan. Salah satu pernyataan publik yang sempat menarik perhatian adalah yang disampaikan oleh Dr. Ryu Hasan, seorang ahli bedah saraf Indonesia, ahli neurosains. Beliau mengatakan bahwa rata-rata kecerdasan masyarakat Indonesia cenderung menurun dalam beberapa tahun terakhir.
Pernyataan ini bukan bermaksud merendahkan masyarakat, tetapi mengajak kita untuk refleksi. Menurut penjelasannya (yang sering ia sampaikan dalam diskusi publik), ada beberapa faktor yang memengaruhi:
- semakin jarangnya masyarakat melakukan aktivitas yang merangsang otak
- kebiasaan mengonsumsi informasi instan
- menurunnya intensitas membaca
- ketergantungan tinggi pada teknologi “jawaban cepat”
- kurangnya aktivitas kognitif mendalam
Jika otak jarang digunakan untuk reasoning, analisis, dan problem solving, maka “jalur-jalur sinaptik” tertentu akan dilemahkan — mirip synaptic pruning negatif.
Analogi AI sangat cocok di sini:
- Parameter yang jarang digunakan akan “dibekukan” (freezing)
- Jalur informasi (sinapsis & dendrit) yang tidak pernah dilewati akan tidak aktif
- Model kehilangan kemampuan yang sebelumnya dimiliki
Otak manusia pun bekerja seperti itu: use it or lose it.
Jika masyarakat kurang membaca, kurang berdiskusi, kurang berpikir kritis, maka jalur-jalur yang berfungsi untuk bernalar akan kurang terstimulasi. Inilah yang menurut Dr. Ryu menjadi faktor penyebab menurunnya kapasitas berpikir populasi/masyarakat secara umum.
Pesan pentingnya jelas: kecerdasan harus dirawat dan dilatih.
Seperti AI yang harus terus melakukan training agar tetap tajam, otak manusia juga harus terus diberi “data latih” berupa:
- membaca
- menulis
- menganalisis
- berdiskusi
- memecahkan masalah
Tanpa Latihan dan belajar, kecerdasan manusia pun bisa menurun.
Penutup
AI modern lahir bukan dari ukuran, tetapi dari organisasi pola, teknik pembelajaran, dan umpan balik berkelanjutan. Sama seperti manusia, kecerdasan AI dibentuk oleh kombinasi potensi bawaan dan pengalaman yang terlatih dengan benar.
Dengan memahami hal ini, kita dapat melihat AI bukan sebagai entitas misterius yang semakin besar jumlah parameternya maka semakin pintar, tetapi sebagai sistem belajar yang membutuhkan:
- arsitektur yang tepat
- data yang benar
- pelatihan yang baik
Dan tentu saja, seperti halnya manusia: yang membuatnya cerdas adalah bagaimana ia berlatih dan belajar, bukan seberapa besar otaknya atau seberapa banyak parameternya.
– AO –
Tangerang Selatan, 24 November 2025
One thought on “KECERDASAN AKAL IMITASI (AI) TIDAK MENJAMIN MEREKA PASTI PINTAR DAN PANDAI”