
– Arief Prihantoro –
“Jika dulu malware menyerang sistem, hari ini ia bisa tertanam di dalam ‘cara sistem melihat’ dunia. Termasuk melihat kita”

Bayangkan sebuah prosesor modern—seperti pada kasus Spectre dan Meltdown—yang begitu cepat hingga tidak lagi menunggu kepastian. Ia tidak hanya mengeksekusi instruksi secara berurutan, tetapi juga menggunakan teknik seperti speculative execution dan out-of-order execution. Artinya, prosesor akan menebak jalur eksekusi yang kemungkinan besar akan terjadi, lalu menjalankannya terlebih dahulu sebelum hasilnya benar-benar dikonfirmasi.
Secara teknis, proses ini melibatkan komponen seperti branch predictor yang terus dilatih berdasarkan pola eksekusi sebelumnya.
Agar lebih mudah dipahami, bayangkan branch predictor seperti satpam yang belajar dari kebiasaan tamu. Jika selama berhari-hari ia melihat orang dengan kartu tertentu selalu boleh masuk ke sebuah ruangan, ia akan mulai membuka pintu lebih cepat—bahkan sebelum memeriksa kartu secara menyeluruh.
Di sinilah penyerang “melatih” CPU.
Agar lebih intuitif, bayangkan branch predictor seperti seorang teman yang terbiasa menebak perilaku Anda.
Jika selama 100 kali berturut-turut terjadi pola yang sama—misalnya setiap hujan Anda selalu membawa payung—maka teman Anda akan mulai yakin: “kalau hujan, pasti bawa payung.”
Lalu pada percobaan ke-101: hujan tetap terjadi, namun Anda sengaja tidak membawa payung.
Teman Anda, yang sudah terbiasa dengan pola sebelumnya, tetap yakin: “pasti bawa.”
Di sinilah terjadi salah prediksi.
Analogi sederhana ini persis menggambarkan apa yang terjadi pada CPU saat diserang dengan teknik Spectre.
Itulah yang disebut “pelatihan”. Bukan pelatihan formal seperti pada AI, tetapi pembentukan kebiasaan prediksi melalui pengulangan pola.
Dalam konteks CPU:
1. Fase training
Penyerang menjalankan kode berulang kali dengan kondisi yang selalu benar. Misalnya, sebuah pengecekan batas array (if index < batas) selalu terpenuhi.
Akibatnya, CPU belajar: “kalau kondisi ini muncul → jalur ini yang diambil.”
Semakin sering diulang, semakin tinggi kepercayaan prediksi tersebut.
2. Fase attack
Penyerang kemudian mengubah sedikit input. Kondisi sebenarnya menjadi salah (misalnya index di luar batas), namun karena CPU sudah “terlatih”, ia tetap mengambil jalur yang sama—setidaknya secara spekulatif. Di momen singkat inilah CPU melakukan akses yang seharusnya tidak diperbolehkan. Meskipun akses ini nantinya dibatalkan secara logika, efeknya sudah terlanjur terjadi pada cache.
Yang penting untuk dipahami: penyerang tidak menggunakan alat khusus. Cukup dengan kode biasa—loop, percabangan sederhana, dan akses data yang tampak normal.
Inilah yang membuat Spectre sangat berbahaya: semua terlihat seperti perilaku program yang sah.
Dengan kata lain, “melatih CPU” hanyalah mengulang pola sampai CPU terbiasa menebak—lalu penyerang sengaja menjebaknya pada saat prediksi itu salah.
Atau dalam satu kalimat:
Kita tidak memaksa CPU— kita hanya membuatnya terlalu percaya diri, lalu memanfaatkannya saat ia keliru. Ketika CPU menghadapi percabangan (misalnya kondisi if-else), ia tidak menunggu hasil evaluasi kondisi, tetapi langsung mengeksekusi salah satu jalur berdasarkan prediksi. Jika prediksi benar, performa meningkat drastis. Jika salah, eksekusi tersebut dibatalkan secara logika—seolah-olah tidak pernah terjadi.
Namun di sinilah celahnya.
Meskipun hasil eksekusi spekulatif dibuang, efek sampingnya pada mikroarsitektur tidak ikut hilang. Salah satu efek paling penting adalah perubahan pada cache CPU. Data yang sempat diakses selama eksekusi spekulatif bisa tersimpan di cache, meninggalkan jejak fisik yang dapat diukur.
Eksploitasi seperti Spectre memanfaatkan hal ini dengan cara “melatih” branch predictor agar membuat prediksi yang salah namun terkontrol. Penyerang kemudian memicu eksekusi spekulatif yang mengakses data rahasia (misalnya di luar batas array). Walaupun akses tersebut secara arsitektural ilegal dan akhirnya dibatalkan, data tersebut sudah sempat mempengaruhi state cache.
Selanjutnya, penyerang menggunakan teknik side-channel timing attack untuk mengukur waktu akses ke lokasi memori tertentu. Perbedaan waktu akses ini mengungkap apakah data tertentu sudah berada di cache atau belum. Dari pola ini, informasi rahasia dapat direkonstruksi sedikit demi sedikit.
Pada Meltdown, mekanismenya sedikit berbeda namun prinsipnya serupa. CPU mengizinkan eksekusi sementara untuk membaca memori kernel sebelum mekanisme proteksi benar-benar menghentikannya. Walaupun secara resmi akses ini tidak diperbolehkan dan akan dibatalkan, data sudah terlanjur masuk ke cache—dan sekali lagi, dapat dieksploitasi melalui side-channel.
Dengan kata lain, kerentanan ini bukan karena CPU “salah”, tetapi karena ia terlalu optimal. Demi mengejar performa, arsitektur prosesor modern mengorbankan isolasi sempurna antara eksekusi sementara dan efek fisiknya.
Timeline Naratif: Evolusi CPU → Lahirnya Spectre & Meltdown
1970s–1980s: Era CPU Sederhana
Eksekusi berurutan (sequential). Tidak ada prediksi, tidak ada spekulasi.
Karakter: Aman secara desain, tapi lambat.
Narasi: “CPU seperti pekerja yang sangat hati-hati—tidak pernah salah, tapi juga tidak cepat.”
1990s: Mulai Masuk Optimasi
Muncul pipelining, branch prediction, dan cache yang lebih kompleks.
Karakter: CPU mulai “menebak” untuk mempercepat kerja.
Narasi: “CPU mulai belajar berpikir ke depan—menebak langkah berikutnya.”
2000s: Out-of-Order & Speculative Execution
Eksekusi paralel, speculative execution makin agresif, cache berlapis (L1/L2/L3).
Karakter: Performa melonjak drastis.
Catatan: Kompleksitas meningkat → efek samping mulai muncul.
Narasi: “CPU tidak lagi menunggu—dia bekerja sebelum diperintah.”
2010–2017: Era Hyper-Optimization
Spekulasi sangat agresif, branch predictor makin pintar, cache dibagi lintas proses.
Karakter: Sangat cepat… tapi mulai “terlalu percaya diri”.
Narasi: “CPU menjadi sangat pintar—bahkan terlalu pintar untuk keamanannya sendiri.”
2018: Terungkapnya Spectre & Meltdown
Bukan bug software, melainkan konsekuensi desain mikroarsitektur modern.
Narasi: “Yang ditemukan bukan kesalahan kecil—tapi celah fundamental dari cara CPU bekerja selama puluhan tahun.”
2018–Sekarang: Era Mitigasi & Kesadaran
Patch OS (mis. KPTI), pembaruan microcode, dan perubahan desain CPU.
Karakter: Trade-off antara keamanan vs performa.
Narasi: “Kita mulai sadar—kecepatan tanpa kontrol bisa menjadi celah.”
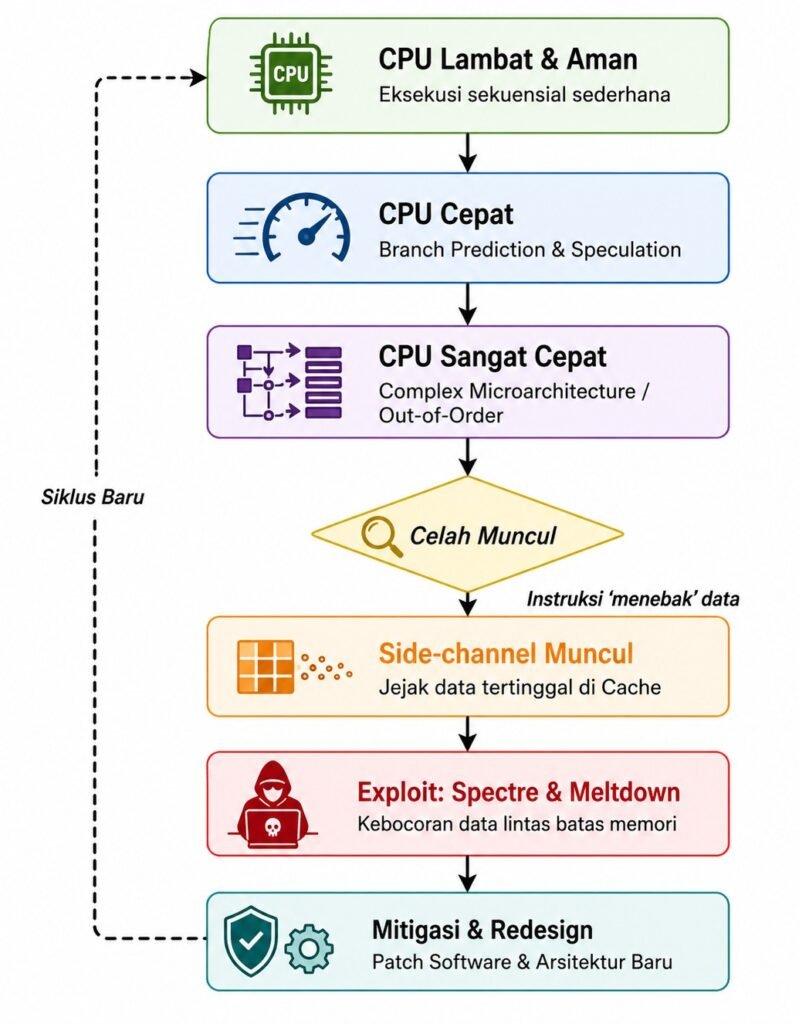
Garis Besar Evolusi:
CPU Lambat & Aman → CPU Cepat (Prediction) → CPU Sangat Cepat (Speculation) → Side-channel → Spectre & Meltdown → Mitigasi
“Spectre dan Meltdown bukan muncul tiba-tiba—mereka adalah hasil dari 30 tahun evolusi performa CPU.”
“Semakin cepat CPU berpikir… semakin besar risiko dia berpikir terlalu jauh.”
Kini, mari kita pindah dari dunia perangkat keras ke dunia persepsi visual—baik manusia maupun kecerdasan buatan.
Ternyata, prinsip yang sama diam-diam terjadi.
Jika CPU bisa “tertipu” karena terlalu cepat mengambil keputusan melalui speculative execution, maka sistem visual—baik otak manusia maupun AI—juga bisa “tertipu” karena terlalu cepat menafsirkan apa yang dilihatnya.
Dengan kata lain, ilusi optik adalah versi “Spectre & Meltdown”-nya dunia persepsi.
Bedanya, bukan data rahasia yang bocor—melainkan makna yang melenceng, atau sengaja dibuat melenceng.
Bayangkan Anda sedang melihat sebuah gambar: dua garis tampak berbeda panjang, padahal sebenarnya sama. Otak Anda “tertipu”. Kita menyebutnya ilusi optik.
Selama ini, fenomena ini dianggap sebagai kelemahan persepsi manusia. Namun, sebuah pertanyaan menarik muncul di era kecerdasan buatan: apakah mesin juga bisa tertipu seperti manusia?
Jawabannya ternyata mengejutkan: ya, BISA.
Untuk memahami hal ini, mari kita gunakan analogi sederhana.
Anggaplah otak manusia seperti seorang detektif berpengalaman. Ia tidak selalu memeriksa setiap detail dari nol, melainkan menggunakan pengalaman masa lalu (intuisi) untuk membuat tebakan cepat. Ketika melihat bayangan atau perspektif tertentu, detektif ini langsung menyimpulkan “ini pasti objek jauh” atau “ini lebih besar”. Sebagian besar waktu, cara ini sangat efisien. Namun, pada kasus tertentu seperti ilusi optik, tebakan cepat ini justru menyesatkan.
Sekarang, bayangkan AI visual—seperti model computer vision atau CNN—sebagai detektif pemula yang dilatih menggunakan jutaan foto. Ia tidak benar-benar memahami dunia, melainkan belajar mengenali pola. Jika sering melihat pola tertentu berkorelasi dengan hasil tertentu, ia akan menggunakannya sebagai aturan.
Masalahnya, pola tidak selalu berarti kebenaran.
Ketika AI melihat gambar ilusi optik, ia juga melakukan “tebakan cepat” berdasarkan pola yang pernah dipelajarinya. Akibatnya, AI bisa menganggap dua warna berbeda padahal sama, atau sebaliknya—persis seperti manusia. Ini menunjukkan bahwa baik otak manusia maupun AI tidak benar-benar melihat dunia apa adanya, melainkan hanya menginterpretasikannya.
Namun, ada perbedaan penting. Jika manusia adalah detektif yang bisa menyadari kesalahannya setelah berpikir ulang, AI sering kali seperti detektif yang terlalu percaya diri.
Dalam beberapa kasus, AI bahkan bisa “melihat” ilusi yang sebenarnya tidak ada. Ia tetap bersikeras bahwa suatu gambar adalah ilusi, meskipun gambar tersebut sudah diperbaiki. Fenomena ini sering disebut sebagai halusinasi pada AI. Dalam konteks ini halusinasi visual AI.
Analogi lain yang membantu adalah membayangkan AI sebagai murid yang belajar dari buku latihan. Jika semua soal latihan memiliki pola tertentu, murid ini akan terbiasa menggunakan pola tersebut untuk menjawab soal. Namun ketika diberikan soal jebakan yang mirip tetapi berbeda konteks, ia bisa salah menjawab karena terlalu bergantung pada pola, bukan pemahaman.
Hal ini menjelaskan mengapa AI bisa tertipu oleh ilusi optik. AI tidak memiliki pemahaman mendalam tentang dunia fisik seperti manusia. Ia hanya mengoptimalkan kemampuannya untuk mengenali pola berdasarkan data yang pernah dilihatnya. Dengan kata lain, AI dilatih untuk menjadi efisien, bukan untuk selalu benar.
Menariknya, fenomena ini justru memberikan wawasan penting. Ilusi optik bukan sekadar “kesalahan”, melainkan konsekuensi dari sistem yang berusaha bekerja cepat dan efisien. Ini adalah trade off antara performa dengan kerentanan.
Baik manusia maupun AI menggunakan strategi yang sama: menyederhanakan realitas agar bisa diproses dengan cepat. Ketika penyederhanaan ini bertemu dengan kondisi tertentu, muncullah ilusi.
Dengan demikian, ketika AI mulai mengalami ilusi optik, itu bukan semata-mata tanda kelemahan. Justru, ini menunjukkan bahwa cara kerja AI mulai menyerupai cara kerja persepsi manusia—meskipun masih jauh dari sempurna.
Pada akhirnya, baik manusia maupun mesin sama-sama “melihat” dunia melalui lensa interpretasi. Dan seperti halnya kacamata yang bisa buram atau bias, interpretasi ini tidak selalu mencerminkan realitas yang sebenarnya.
Namun, ada satu lapisan fenomena yang lebih dalam—dan sekaligus lebih mengganggu.
Fenomena ini sering disebut sebagai “halusinasi” pada AI.
Jika sebelumnya kita membahas bagaimana AI bisa tertipu oleh ilusi optik—yakni ketika stimulus visual memang ambigu—maka pada tahap ini AI tidak hanya salah tafsir, tetapi juga bisa “melihat” sesuatu yang sebenarnya tidak ada.
Bayangkan seorang murid yang terlalu menghafal pola soal. Ketika diberikan soal baru yang sedikit berbeda, ia bukan hanya salah menjawab—tetapi justru merasa yakin bahwa ia melihat pola yang familiar, padahal pola itu tidak benar-benar ada.
Dalam konteks Visual AI, hal ini terjadi ketika model terlalu mengandalkan representasi internal yang dibentuk dari data pelatihan. Ketika menghadapi input baru, model bisa memaksakan interpretasi berdasarkan pola lama, meskipun tidak relevan.
Akibatnya, model dapat menyimpulkan keberadaan objek, pola, atau bahkan “ilusi” yang sebenarnya sudah tidak ada pada gambar tersebut.
Berbeda dengan manusia yang masih bisa berhenti, meninjau ulang, lalu menyadari kesalahan persepsinya, model AI cenderung tetap “percaya diri” pada hasil prediksinya. Ia tidak memiliki mekanisme kesadaran reflektif untuk meragukan interpretasinya sendiri.
Jika kita tarik kembali ke analogi Spectre dan Meltdown, fenomena ini terasa semakin jelas.
Pada kasus eksploitasi prosesor, CPU mengeksekusi sesuatu yang seharusnya tidak terjadi, lalu meninggalkan jejak mikroarsitektur pada cache yang bisa dieksploitasi.
Pada Visual AI, model “mengeksekusi interpretasi” yang seharusnya tidak terbentuk, lalu menghasilkan keluaran yang tampak valid—padahal berangkat dari asumsi yang keliru.
Keduanya menunjukkan pola yang sama:
bahwa sistem yang terlalu dioptimalkan untuk kecepatan dan efisiensi… sering kali harus membayar harga berupa distorsi terhadap realitas.
Dengan demikian, ilusi dan halusinasi pada AI bukan sekadar kesalahan teknis. Mereka adalah konsekuensi logis dari sebuah sistem yang dirancang untuk berpikir cepat— bukan selalu untuk berpikir benar.
Paralel: “Melatih CPU” vs “Training Bias” pada Model AI (CNN)
Menariknya, mekanisme “melatih CPU” pada Spectre memiliki kemiripan struktural dengan cara model AI—khususnya CNN—belajar dari data, termasuk pada tugas sensitif seperti deteksi wajah atau deteksi emosi.
Bayangkan kembali proses training pada Spectre: penyerang mengulang pola input yang sama hingga branch predictor menjadi sangat percaya diri terhadap satu jalur. Ketika pola itu dibalik sedikit, CPU tetap mengikuti kebiasaan lamanya—dan di situlah celah terjadi.
Hal serupa terjadi pada pelatihan model AI.
Dalam CNN, model belajar dari dataset melalui pengulangan contoh. Jika dataset memiliki bias—misalnya lebih banyak contoh ekspresi tertentu pada kondisi pencahayaan, sudut wajah, atau subjek tertentu—maka model akan “terlatih” untuk mengasosiasikan pola-pola tersebut sebagai penentu utama.
Secara analogis:
– Spectre (CPU): mengulang pola input → prediksi menjadi percaya diri
– CNN (AI): mengulang data pelatihan → bobot fitur menjadi dominan
Masalah muncul ketika model menghadapi kondisi baru yang sedikit berbeda. Seperti CPU yang tetap mengambil jalur lama meski kondisi sudah berubah, model AI juga bisa tetap mengandalkan fitur yang secara intuitif “terlalu dipercaya”—meskipun tidak lagi relevan.
Contoh pada micro-expression:
Model dilatih banyak pada wajah dengan pencahayaan frontal.
Ketika diuji pada pencahayaan samping, Model bisa salah membaca ekspresi karena tetap “mengharapkan” pola lama.
Atau lebih halus lagi:
Model mengaitkan kerutan halus tertentu dengan emosi tertentu.
Padahal pada konteks berbeda, kerutan itu bukan indikator emosi.
Inilah yang disebut training bias—ketika distribusi data pelatihan membentuk kebiasaan interpretasi yang terlalu kaku.
Jika kita tarik paralel langsung:
1. Fase Training
Spectre: mengulang input aman → melatih branch predictor
CNN: mengulang dataset → melatih bobot dan fitur
2. Fase Eksploitasi / Generalisasi
Spectre: input diubah sedikit → CPU tetap salah prediksi
CNN: data baru berbeda → model tetap pakai pola lama
Dampak
Spectre: akses ilegal sementara → bocor via cache
CNN: interpretasi keliru → misclassification / false emotion
Keduanya memperlihatkan prinsip yang sama:
bahwa sistem yang belajar dari pola berulang akan cenderung “terkunci” pada ekspektasi— dan ketika realitas sedikit menyimpang, kesalahan bukan hanya mungkin terjadi, tetapi sistematis.
Dengan perspektif ini, kesalahan pada model Visual AI (misal: micro-expression) bukan sekadar noise atau keterbatasan teknis.
Ia adalah konsekuensi dari cara model “dilatih”— sama seperti CPU yang menjadi rentan bukan karena rusak, tetapi karena terlalu efisien dalam belajar dari kebiasaan.
Namun, jika kita melangkah lebih jauh, fenomena ini tidak berhenti pada tingkat persepsi visual semata. Ia terhubung dengan sesuatu yang lebih luas—apa yang dapat kita sebut sebagai “déjà vu algoritmik” (seperti sudah pernah saya tulis pada beberapa artikel sebelumnya).
Bayangkan kembali pengalaman déjà vu pada manusia: sebuah momen ketika sesuatu terasa sangat familiar, seolah-olah pernah terjadi sebelumnya, padahal secara faktual belum pernah dialami. Dalam banyak penjelasan ilmiah, hal ini terjadi karena sistem “rasa familiar” dalam otak bekerja lebih cepat daripada sistem verifikasi memori.
Menariknya, pola ini identik dengan apa yang terjadi pada Visual AI.
Model tidak benar-benar memahami gambar dari nol. Ia mencocokkan input dengan pola yang sudah dipelajari sebelumnya. Ketika pola tersebut aktif terlalu cepat atau terlalu dominan, interpretasi yang muncul terasa “benar”—meskipun sebenarnya tidak akurat.
Di sinilah relevansi dengan déjà vu algoritmik menjadi jelas.
Jika ilusi optik adalah kondisi ketika AI salah menafsirkan realitas karena pola yang menyesatkan, maka déjà vu algoritmik adalah kondisi ketika sistem secara lebih luas—melalui algoritma—membentuk pengalaman yang terasa familiar bahkan sebelum realitas itu benar-benar dipahami.
Dengan kata lain: makna mendahului pengalaman.
Pada ilusi optik, hal ini terjadi dalam skala mikro—pada level piksel, bentuk, dan warna.
Pada déjà vu algoritmik, hal ini terjadi dalam skala makro—pada level pengalaman, informasi, dan bahkan realitas sosial yang dikonsumsi manusia.
Keduanya berbagi mekanisme yang sama:
sebuah sistem berbasis prediksi yang terlalu mengandalkan pola masa lalu untuk menafsirkan input saat ini.
Jika kita tarik kembali ke analogi awal tentang Spectre dan Meltdown, kita melihat pola yang konsisten di tiga domain berbeda:
1. Pada prosesor: eksekusi mendahului validasi → menghasilkan kebocoran data
2. Pada Visual AI: interpretasi mendahului realitas → menghasilkan ilusi
3. Pada sistem algoritmik sosial: makna mendahului pengalaman → menghasilkan déjà vu
Ketiganya bukan sekadar kebetulan.
Mereka adalah manifestasi dari prinsip yang sama:
bahwa dalam sistem yang dioptimalkan untuk kecepatan dan efisiensi, realitas tidak lagi sepenuhnya “dibaca”… melainkan dikonstruksi.
Dan dalam konstruksi tersebut, kesalahan bukanlah anomali— melainkan konsekuensi yang tak terelakkan sebagai trade off.
Dari Ilusi ke Eksploitasi: Embedded AI, Backdoor, dan “Tidak Melihat”
Jika ilusi optik dan halusinasi menunjukkan bagaimana sistem visual dapat salah menafsirkan realitas, maka pada sistem AI embedded (edge AI)—seperti kamera pintar, perangkat medis, atau sistem kendaraan—kerentanan ini dapat naik level: dari kesalahan persepsi menjadi vektor eksploitasi.
Bayangkan sebuah kamera pintar atau device IoT yang menjalankan model deteksi wajah dan perilaku secara langsung di perangkat. Sistem tampak normal: akurat, stabil, dan responsif.
Namun, ternyata sejak awal model yang ditanamkan telah dimodifikasi. Bukan untuk gagal… melainkan untuk “tidak melihat” kondisi tertentu. Misalnya, ketika pola wajah atau atribut spesifik muncul, sistem tetap memproses gambar—tetapi tidak pernah mengklasifikasikannya sebagai ancaman.
Ini bukan sekadar error. Ini adalah backdoor pada model.
Mekanisme Teknis (Ringkas)
Dalam keamanan AI, dikenal beberapa konsep:
– Model tampering: bobot model diubah
– Backdoor/Trojan: model berperilaku normal, kecuali saat “trigger” tertentu muncul
– Adversarial pattern: pola kecil yang menggeser keputusan model
Pada skenario backdoor, pelaku menyisipkan “trigger” (bisa berupa pola visual halus). Saat trigger hadir, aktivasi fitur dalam jaringan saraf bergeser sehingga keputusan akhir berubah—tanpa mengganggu performa pada data normal.
Paralel dengan Ilusi Visual AI
– Ilusi/halusinasi: model salah menafsirkan karena bias pola → misperception
– Backdoor embedded: model diarahkan untuk salah menafsirkan pada kondisi tertentu → weaponized misperception
Keduanya berbagi akar yang sama: dominasi representasi internal (pola) atas realitas input.
Kenapa Lebih Berbahaya di Edge?
– Tidak ada inspeksi cloud yang intensif
– Update (firmware atau model) terbatas / jarang
– Sulit melakukan verifikasi integritas model di perangkat
– Sistem tetap tampak “normal” pada mayoritas kondisi
Akibatnya, backdoor dapat bertahan lama tanpa terdeteksi.
Insight Kunci
Jika sebelumnya kita khawatir sistem bisa “tertipu”, maka di sini sistem bisa “diajarkan untuk tertipu pada saat yang dipilih”.
Dengan kata lain:
bukan hanya persepsi yang keliru— melainkan kesalahan yang sengaja dirancang sejak awal, sejak menyusun arsitektur model melalui metadatanya.
“Jika dulu malware menyerang sistem, hari ini ia bisa tertanam di dalam ‘cara sistem melihat’ dunia. Termasuk melihat kita”
Skenario End-to-End: Dari Data hingga Eksploitasi Nyata
Untuk memahami bagaimana kerentanan ini benar-benar terjadi di dunia nyata, bayangkan sebuah alur serangan yang dimulai jauh sebelum sistem digunakan.
Tahap 1 — Data Poisoning (Akar Masalah)
Segalanya dimulai saat model dilatih.
Dataset wajah dan ekspresi dikumpulkan untuk melatih sistem deteksi. Namun, penyerang secara diam-diam menyisipkan data dengan pola tertentu pada metadata pelatihan (misalnya aksesori visual spesifik), tetapi diberi label sebagai kondisi “normal”.
Model pun belajar sesuatu yang keliru:
“Jika pola ini muncul → bukan ancaman.”
Di sini, kesalahan tidak terjadi karena sistem gagal belajar— tetapi karena sistem diajarkan hal yang salah.
Tahap 2 — Training: Bias Menjadi Kebiasaan
Selama proses training, jaringan saraf memperkuat bobot fitur dari data tersebut.
Pola berbahaya itu kini menjadi bagian dari “pengetahuan” model.
Seperti CPU yang dilatih melalui pengulangan, model AI juga membentuk kebiasaan interpretasi.
Tahap 3 — Deployment ke Embedded System
Model yang tampak akurat kemudian di-deploy ke perangkat nyata: kamera CCTV pintar, sistem keamanan, IoT atau perangkat edge lainnya.
Semua berjalan normal. Tidak ada error. Tidak ada tanda mencurigakan.
Namun tanpa disadari, bias tersebut ikut tertanam permanen ke Embedded System.
Tahap 4 — Trigger: Serangan Dimulai
Suatu saat, penyerang muncul dengan pola visual yang sama seperti yang telah “ditanamkan” dalam training.
Sistem tetap bekerja: mendeteksi wajah, memproses citra, dan menjalankan model.
Namun…… ia tidak pernah menganggapnya sebagai ancaman.
Tahap 5 — Eksploitasi: Sistem Melihat Tapi Tidak Memahami
Secara teknis, semua pipeline berjalan normal.
Namun keputusan akhir telah dibelokkan oleh bias yang ditanam sejak awal.
Hasilnya adalah false negative—ancaman yang tidak pernah terdeteksi.
Tahap 6 — Kenapa Tidak Terdeteksi?
Karena:
– Akurasi tetap tinggi dalam kondisi normal.
– Kesalahan hanya muncul pada kondisi spesifik.
– Tidak ada crash atau error log.
– Sistem terlihat sepenuhnya sehat.
Inilah yang membuatnya berbahaya.
Bukan karena sistem gagal… melainkan karena sistem berhasil menjalankan sesuatu yang salah secara sengaja.
Insight Kunci
Jika sebelumnya kita berbicara tentang ilusi dan halusinasi sebagai kesalahan persepsi, maka pada tahap ini kita melihat sesuatu yang lebih dalam:
“kesalahan tersebut dapat direkayasa, ditanamkan, dan diaktifkan sesuai kebutuhan.”
Dengan kata lain:
bukan hanya sistem yang bisa tertipu— sistem bisa diajarkan untuk tertipu pada waktu yang tepat.
“Ini bukan serangan pada sistem. Ini adalah serangan pada cara sistem memahami dunia.”
Risiko Jika Kerentanan Ini Sengaja Ditanamkan
Jika pada skenario sebelumnya kerentanan muncul karena manipulasi data atau model, maka ada kemungkinan yang lebih serius: kerentanan tersebut sengaja dirancang sejak awal dalam sistem AI embedded.
Ini mengubah posisi masalah—dari sekadar serangan eksternal menjadi risiko desain dan kepercayaan.
Bentuk Risiko:
1. Kontrol Tersembunyi (Hidden Control)
Model dapat dirancang untuk merespons pola tertentu yang hanya diketahui oleh pihak tertentu.
Akibatnya, sistem yang terlihat independen sebenarnya memiliki “tombol rahasia” yang dapat mengubah perilakunya.
2. Selective Blindness (Kebutaan Selektif)
Sistem dapat dibuat untuk tidak mendeteksi objek, wajah, atau perilaku tertentu.
Dalam konteks keamanan, ini berarti:
“ancaman tertentu bisa ‘melewati sistem’ tanpa pernah terdeteksi.”
3. Asymmetric Power
Pihak yang mengetahui trigger (misalnya produsen, pemerintah otoriter atau konteks spionase) memiliki keunggulan absolut dibanding pengguna sistem.
Ini menciptakan ketimpangan kontrol yang tidak terlihat.
4. Supply Chain Attack Level Baru
Jika model sudah disusupi sebelum distribusi, maka seluruh perangkat yang menggunakan model tersebut ikut terkompromi.
Ini memperluas serangan dari satu sistem menjadi skala ekosistem.
Dampak Strategis:
– Kepercayaan terhadap AI menjadi rapuh
– Verifikasi sistem menjadi sangat sulit
– Audit tradisional tidak cukup (karena sistem tampak normal)
– Risiko pada sektor kritis (keamanan, medis, transportasi cerdas)
Jika sebelumnya kita berbicara tentang:
– sistem yang bisa tertipu
– sistem yang bisa diajarkan untuk tertipu
maka pada tahap ini:
“sistem bisa dirancang untuk salah sejak awal.”
“Masalah terbesar bukan ketika AI salah… melainkan ketika AI sengaja dibuat untuk salah— dan kita tidak pernah menyadarinya.”
AO
Tangerang Selatan, 3 Mei 2026
Artikel sebelumnya:
Déjà Vu ALGORITMIK – Masyarakat Informatika Sosial Indonesia: Mengeksploitasi AI Visual Melalui Kerentanan Ilusi Optik AI Intuisi Manusia vs Intuisi Mesin – Masyarakat Informatika Sosial Indonesia: Mengeksploitasi AI Visual Melalui Kerentanan Ilusi Optik AI